
Overview
In this post, I will go through 12 core Apache Flink concepts to better understand what it does and how it works. This article could perfectly serve as a beginner's overview of Flink and Streaming engine terminology.
1.
What is Apache
Flink?
At first glance, the origins of Apache Flink can be traced back to
June 2008 as a researching project of the Database Systems and Information
Management (DIMA) Group at the Technische Universität (TU) Berlin in Germany.
Apache Flink is an open source platform for distributed stream and
batch data processing, initially it was designed as an alternative to MapReduce
and the Hadoop Distributed File System (HFDS) in Hadoop origins.
According to the Apache Flink project, it is an open source platform for distributed stream and batch data
processing. Flink’s core is a streaming dataflow engine that provides data
distribution, communication, and fault tolerance for distributed computations
over data streams. Flink also builds batch processing on top of the streaming
engine, overlaying native iteration support, managed memory, and program
optimization.”
What
does Flink offer?
Streaming:
·
High Performance & Low Latency
·
Support for Event Time and Out-of-Order Events
·
Exactly-once Semantics for Stateful Computations
·
Highly flexible Streaming Windows
·
Continuous Streaming Model with Backpressure
·
Fault-tolerance via Lightweight Distributed Snapshots
Batch and Streaming in One System
·
One Runtime for Streaming and Batch Processing
·
Memory Management
·
Iterations and Delta Iterations
·
Program Optimizer
Ecosystem
·
Broad Integration (Yarn, Hadoop, HDFS, Kafka, others)
What
are Flink’s components?
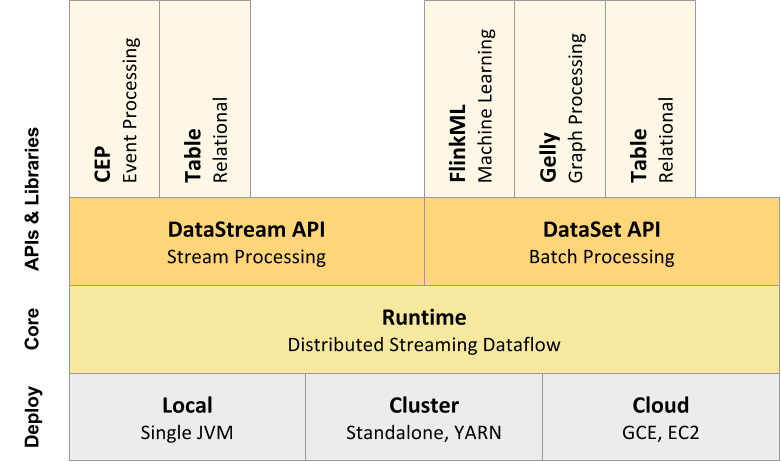
Flink stack offers application programming interfaces (APIs) (in
Java/Scala/Python), shell console, tools and Libraries to develop new data-intensive
applications over Flink engine.
2.
Deploy Layer /
What does Flink’s Deploy Layer do?
Apache Flink can execute programs in a diversity of context, such as
standalone, or embedded in other programs. The execution could be in a local
Java Virtual Machine JVM or in different clusters with many nodes.
3.
Core Layer (Runtime)
/ What does Flink’s Core Layer do?
The Distributed Streaming Dataflow layer receives a program like a
generic parallel data flow with arbitrary tasks, which inputs and outputs are
data streams. This tasks are called “JobGraph”.
4.
Stream
Processing / What is stream processing?
Stream processing is a new sight of processing, the business logic is
applied to every transaction that is being recorded in real-time in a system,
for example E-commerce, the Internet of Things (IofT) with various sensors that
emit data online, online monitoring of traffic in a city, telecom, banking,
etc. In other words, stream processing applies business logic to each event
that is being captured online in instead of store whole events and hence
process it as a batch. The highlight of process in this way is that the
analysis will show the real or online state of the data at this instance, that
is in real-time with unbounded data.
5.
Batch
Processing
Bath processing is processing a huge volume of bounded data at once.
The steps need for processing are called batch jobs. Batch jobs could be stored
up during working hours for example working hour and hence executed during the
evening, or even during weeks or months and executed on weekend or once a
month. The classic example of batch processing is how the credit card companies
process billing. The client does not receive a bill for each transaction,
usually a customer receives the billing each month when whole data has been
collected. One example for managing it is Hadoop that provides
map Reduce as a processing tool for these large scale files which can be months
or years of data stored.
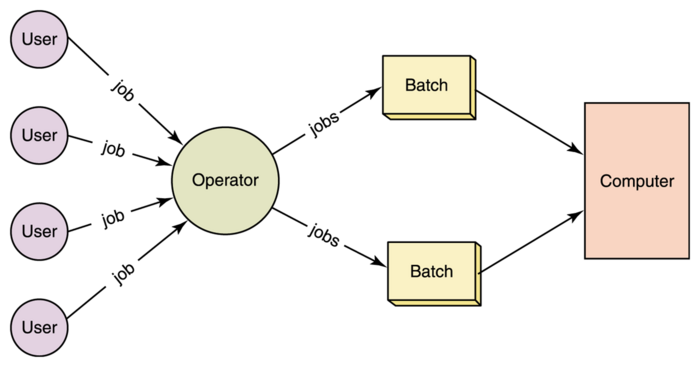
[1]
6.
Flink
DataStream API (for Stream Processing)
Data Stream is the main API that offers Apache Flink, and what makes
difference with its competitors. DataStream API allows develop programs (in
Java, Scala and Python) that implement transformations on data streams (see
examples in 6.1). The data streams are initially created from multiple sources
such as message queues, socket streams or files. The results of the data
streams return via Data Sinks, which allow write the data to distributed files
or for example command line terminal.
6.1 Examples of
transformations in Flink:
·
Map
·
FlatMap
·
Filter
·
KeyBy
·
Reduce
·
Fold
·
Aggregations
·
Window
·
WindowAll
·
Window Apply
·
Window Reduce
·
Window Fold
·
Aggregations on windows
·
Union
·
Window Join
·
Window CoGroup
·
Connect
·
CoMap, CoFlatMap
·
Split
·
Select
·
Iterate
·
Extract Timestamps
·
Project (for data streams of Tuples)
7.
Flink DataSet
API (for Batch Processing)
Apache Flink provides a DataSet API that allows to developers can
develop programs (in Java, Scala and Python), that implement transformations on
data sets (see examples in 7.1). The data sets are initially created from multiple
sources such as File-Based, Collection-Based, Socket-based, Custom. The results
of the data sets return via Data Sinks, which allow write the data to
distributed files or for example command line terminal.
7.1 Examples of
transformations in Flink:
·
Map
·
FlatMap
·
Map Partition
·
Filter
·
Reduce
·
ReduceGroup
·
Aggregate
·
Distinct
·
Join
·
OuterJoin
·
CoGroup
·
Cross
·
Union
·
Rebalance
·
Hash-Partition
·
Range-Partition
·
Custom Partitioning
·
Sort Partition
·
First-n
·
Project (for data streams of Tuples)
·
MinBy / MaxBy (for data streams of Tuples)
8.
FlinkCEP –
Complex event processing for Flink
Apache Flink includes a complex event processing library that allows
to developers detect complex event patterns in a stream of endless data. With
the analysis of Matching sequences data scientist can construct complex events
and do a deep analysis of the data.
9.
Streaming SQL
Streaming SQL is a query language that extends the traditional SQL
capabilities to process real-time data streams. The main challenge is
incorporate aggregations, windows and time semantics on streams. Nowadays,
Apache Flink community is working with Apache Calcite community to develop a
new model for solve these challenges and improvements.
10.
Flink Table API
& SQL
Flink Table API and SQL are experimental features focusing in
Streaming SQL that allow to work with SQL-like expressions for relational
stream and batch processing. The Table API and SQL interface operate on a
relational Table abstraction and provide tight integration with Flink DataSet
API.
11.
Flink ML
(Machine Learning)
Apache Flink provides an extensive and newly scalable Machine
Learning (ML) library for Flink developers, the main two goals of Flink ML are
to help to developers keep glue code to a minimum and second goal is to make it
easy to use providing detailed documentation with examples. Flink ML allows to
data scientist to test their algorithms and models locally with a subset of the
total data and hence with the same written code this can be executed at a much
larger scale in a cluster setting.
The Machine learning algorithms supported at the moment are:
Supervised Learning
SVM using
Communication efficient distributed dual coordinate ascent (CoCoA)
Multiple linear
regression
Optimization
Framework
Data Preprocessing
Polynomial
Features
Standard Scaler
MinMax Scaler
Recommendation
Alternating
Least Squares (ALS)
Utilities
Distance
Metrics
12.
Flink Gelly
(Graph Processing)
Gelly is a Graph API for Flink that contains variety of methods and
tool (such as graph transformations and utilities, iterative graph processing,
library of graph algorithms) for doing graph analysis applications in Flink.
Gelly can be seamlessly mixed with the DataSet Flink API for developing
programs that use both record-based and graph-based analysis.
Flink Gelly provide the next Graph Methods:
·
Graph Properties (e.g. getVertexIds, getEdgelds, numberOfVerices,
numberOfEdgest, etc)
·
Transformations (e.g. map, filter, join, subgraph, union, difference,
reverse, undirected, getTriplets, etc.)
·
Mutations (e.g. add vertex, add edge, remove vertex, remove edge)
·
Neighborhood Methods.
Some Algorithms provides in Flink Gelly:
·
PageRank
·
Single Source Shortest Paths
·
Label Propagation
·
Weakly Connected Components
·
Community Detection
·
Triangle Count & Enumeration
·
Graph Summarization
13.
BONUS term
Blink (Alibaba Flink)
Blink is a project (improvements to Flink) from Alibaba Group, which
operates the world’s largest online marketplace and it profits bigger than
Amazon and eBay combined. These improvements include better changes in Flink
Table API (such as unification of SQL layer for batch and streaming, adding
features stream-stream join, aggregations, windowing, retraction) and Runtime
Compatibility with Flink API and Ecosystem (such as new runtime architecture on
YARN, optimized state, checkpoint & failover, reliable and production
quality and others).
Summary
Apache Flink could be considering as the 4th generation of Big Data
Framework, instead of waiting for a long cycle of batch processing until data
could be available, data scientist can work in real-time with data generated
and processed continuously.
References:
[1] Batch Processing, http://www.itrelease.com/2012/12/what-are-advantages-and-disadvantages-of-batch-
processing-systems/
References:
[1] Batch Processing, http://www.itrelease.com/2012/12/what-are-advantages-and-disadvantages-of-batch-
processing-systems/
No comments:
Post a Comment